Method Overview
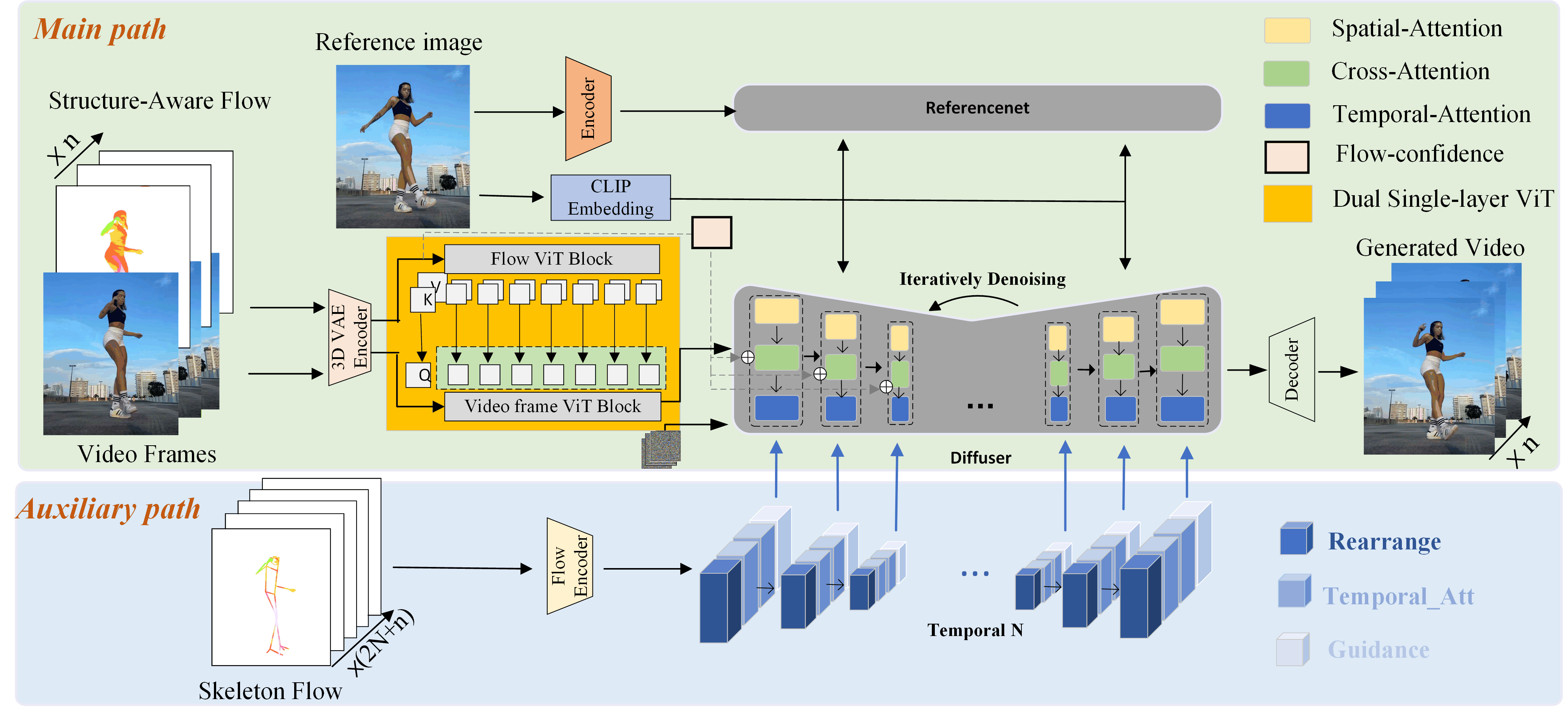
Given reference image and driving video, our method extracts both the Structure-Aware Flow and the Skeleton Flow as motion. Structure-Aware Flow sequences ORGB ∈ ℝH × W × 3 are interleaved with the corresponding video frames I ∈ ℝH × W × 3 to form pseudo-continuous sequence which denoted as X = [I1, ORGB1, I2, ORGB2, ..., In, ORGBn] in the main path. After encoding, dual single-layer ViT module aligns and fuses motion and appearance features. The preprocessed skeleton flow sequence (2N+n) is encoded and injected into the auxiliary path (N is the half-length of adaptive window). It integrates the global motion priors to guide local human motion generation within the model. Flow-confidence mechanism leverages optical flow intensity to derive confidence scores, enabling adaptive modulation of motion guidance across different body regions.